Introduction
Amazon S3-Select is a feature of Amazon S3 that was launched and became generally available in 2018. Amazon S3 is a popular storage service that is relatively simple to use, easy to scale, couples with other AWS services, and stores objects of nearly any file type. But the disadvantage of Amazon S3 was that we could not retrieve subsets of data (i.e., you could only retrieve the whole file).
This is where S3-Select came to the rescue. Imagine you wanted to import only the first 500 lines from a CSV file 5000. With the help of S3-Select, you can now retrieve only the data you want, which was otherwise not an option, and you would have to download the whole object and filter the data locally.
That is why S3 was used not as a database but as a storage service. With the feature of S3-Select, it can also serve as a database for a read operation for small applications.
How does S3-Select work?
With Amazon S3 Select, you can use simple structured query language (SQL) statements to filter the contents of an Amazon S3 object and retrieve just the subset of data that you need. By using Amazon S3 Select to filter this data, you can reduce the amount of data that Amazon S3 transfers, which reduces the cost and latency of retrieving this data.
Amazon S3 Select works on CSV, JSON, or Apache Parquet format objects. It also works with objects compressed with GZIP or BZIP2 (for CSV and JSON objects only) and server-side encrypted objects. You can specify the format of the results as either CSV or JSON, and you can determine how the records in the result are delimited.
It is possible to query s3 files using s3-select from AWS console, CLI (cloud shell or local terminal), and python sdk. We will see all these methods later in the blog.
Requirements and limitations of S3-Select
- You must have s3:GetObject permission for the object you are querying.
- If the object you are querying is encrypted with a customer-provided encryption key (SSE-C), you must use HTTPS and provide the encryption key in the request.
- The maximum length of a SQL expression is 256 KB.
- The maximum length of a record in the input or result is 1 MB.
- Amazon S3 Select can only emit nested data using the JSON output format.
- You cannot specify the S3 Glacier Flexible Retrieval, S3 Glacier Deep Archive, or REDUCED_REDUNDANCY storage classes.
- Amazon S3 Select supports only columnar compression using GZIP or Snappy. Amazon S3 Select doesn’t support whole-object compression for Parquet objects.
- Amazon S3 Select doesn’t support Parquet output. You must specify the output format as CSV or JSON.
- The maximum uncompressed row group size is 512 MB.
- You must use the data types specified in the object’s schema.
- Selecting a repeated field returns only the last value.
Querying CSV/Json Data
Using Console:
- To start with, open S3 in your AWS account console and create/select a bucket that has an already existing csv/Json file in it. Now, click on Actions and select Query with S3 Select.
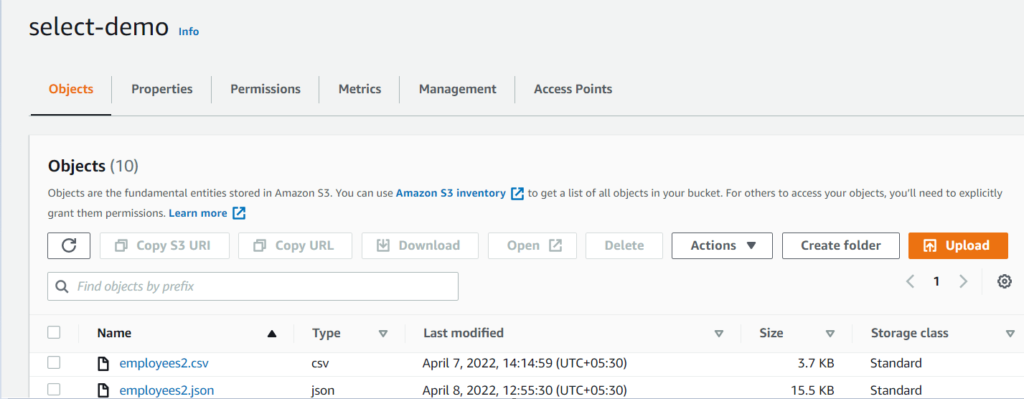
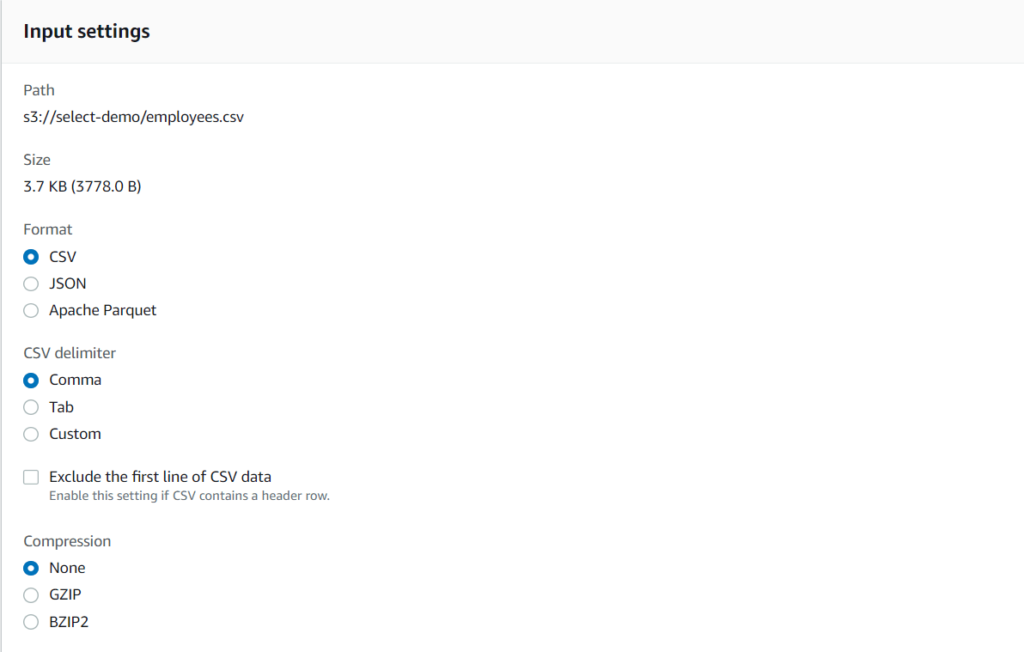
2. You can see the following input settings. Select the Format, type of CSV Delimiter, and Compression type, which in our case is none, and we will see later in this blog how compression helps in faster data retrieval. After this, you can also specify output settings.
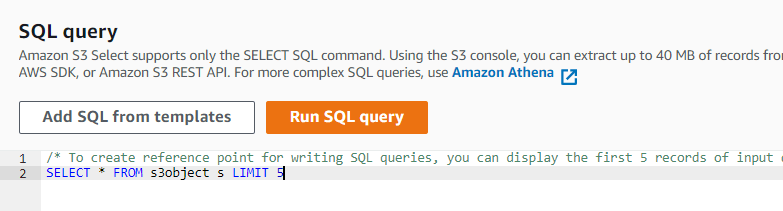
3. Now, write a SQL query to get only 5 lines from the contents of the file.
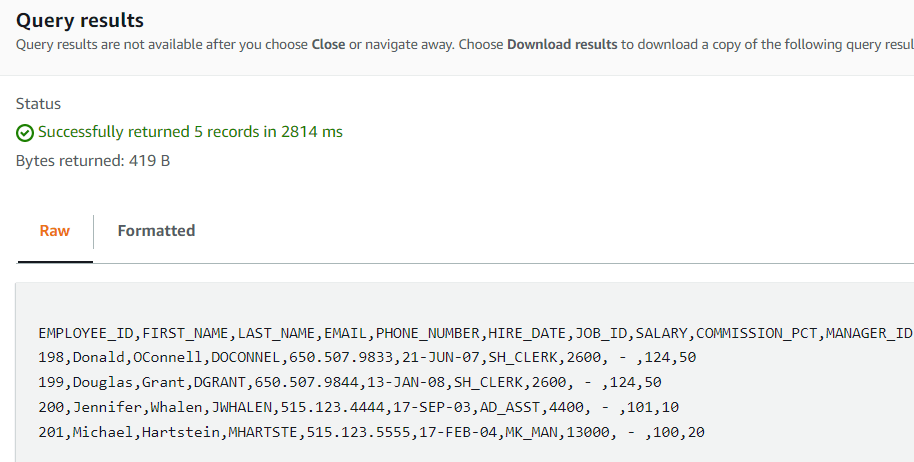
4. As you can see in the results, we got only 5 lines from the whole file content. You can also download this filtered data and not the whole file contents; that is why s3-select is very handy.
5. S3-Select works for only read queries and not for write/update queries. Let \’s check out what queries we can perform using s3-select. We will be taking an example of retrieving employee data.
6. CSV File Queries
a. Getting all contents of file:
SELECT * FROM s3object s
b. Getting only limited lines from a file(e.g. 10 lines):
SELECT * FROM s3object s LIMIT 10
c. Getting EMPLOYEE_ID and FIRST_NAME from the file( Enable exclude first line whenever you specify column name in your queries):
SELECT EMPLOYEE_ID , FIRST_NAME FROM s3object s
d. Getting column1 and column2 from the file( Disable exclude first line whenever you specify column number in your queries) :
SELECT s._1, s._2 FROM s3object s
e. Getting a particular first name:
SELECT * FROM s3object s WHERE s.FIRST_NAME = \’Donald\’
f. Using “like” instead of “equals to”, you need to place the string between percent signs:
SELECT * FROM s3object s WHERE s.FIRST_NAME like \’%Donald%\’
g. Casting as Integer because S3-select treats every data as string:
SELECT * FROM s3object s WHERE CAST(s.SALARY as INTEGER) = 2600
h. Casting as Float because S3-select treats every data as string:
SELECT * FROM s3object s WHERE CAST(s.INTEREST as FLOAT) = 3.5
i. Using logical operators (see s3-select documentation for different types of operators):
SELECT * FROM s3object s WHERE CAST(s.SALARY as INTEGER) > 2600 AND CAST(s.SALARY as INTEGER) < 4000
7. Json File Queries: It is the same as for CSV queries but the FROM command changes and you have to specify the object that is being queried, rest everything remains the same.
a. Getting all contents of file:
SELECT * FROM s3object[].employees[] s
b. Getting only limited objects from a file(e.g. 10 objects):
SELECT * FROM s3object[].employees[] s LIMIT 10
c. Using average function to get average salary from all objects:
SELECT AVG(s.salary) FROM s3object[].employees[] s
d. Getting number of objects/entries in a file salary using count function (you can also use min, max and sum for the respective purpose):
SELECT COUNT() FROM s3object[].employees[*] s
8. Compression of a particular file will help faster data retrieval with fewer data retrieved bytes, reducing the data read cost. It supports GZIP and BZIP2 compression types.
Using Command Line Interface:
- It is also possible to get data from s3-select using CLI, we have to firstly attach the following bucket policy to the bucket that is being queried.
{
\"Version\": \"2012-10-17\",
\"Statement\": [
{
\"Sid\": \"S3Access\",
\"Effect\": \"Allow\",
\"Principal\": {
\"AWS\": \"arn:aws:sts::***:assumed-role/***\"
},
\"Action\": \"s3:*\",
\"Resource\": \"arn:aws:s3:::select-demo/*\"
}
]
}
- After that use the following code and paste it in your CLI to get the results.
aws s3api select-object-content \
–bucket select-demo \
–key employees.csv \
–expression \”select * from s3object limit 2\” \
–expression-type \’SQL\’ \
–input-serialization \'{\”CSV\”: {FileHeaderInfo\”: \”USE\”}, \”CompressionType\”: \”NONE\”}\’ \
–output-serialization \'{\”CSV\”: {}}\’ \”csv_output.csv”
3. In the above command we are basically connecting to s3-object using API call and providing the bucket name, key name, query expression and other settings used in s3-select.

4. Now open the “csv_output.csv” file where you can see all the results.

Using Python SDK:
- You can also use any other language, in this we are going to python sdk for s3-select queries. Following is the code for querying s3 objects using s3-select.
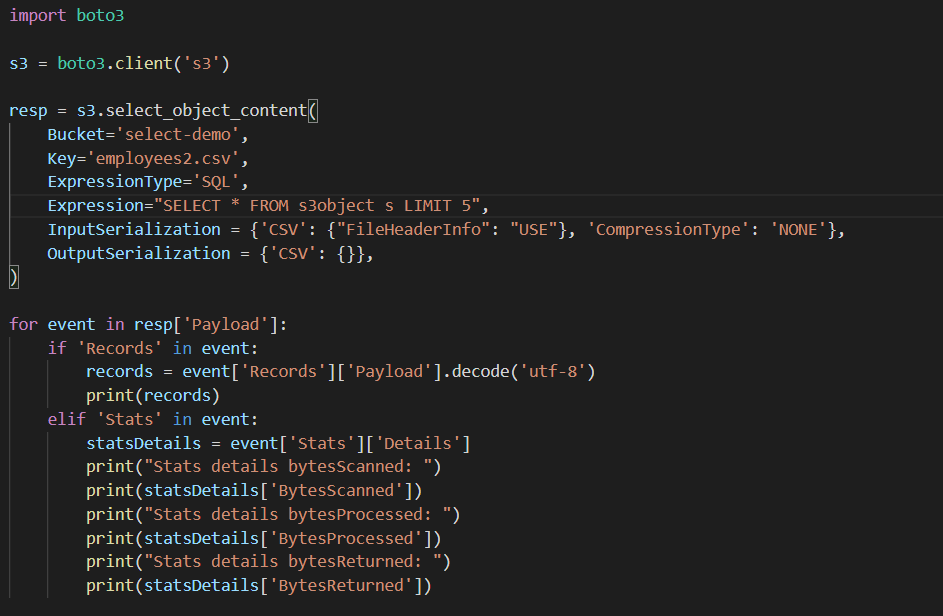
2. Run the above code with the sql expression you want and you will get the following results
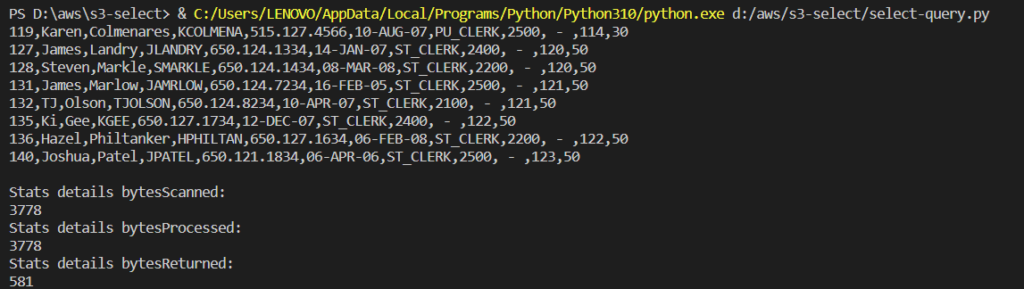
Run the code with the sql expression
3. From above results you can see the stats of byteScanned, bytesProcessed and bytesReturned which is crucial for faster reads and cost optimization. That is how s3-select helps in both ways reducing read cost and retrieval of only filtered data so you don’t have to do it locally.
4. Now what if we zip the same file using GZIP and upload it to s3 and then query it.
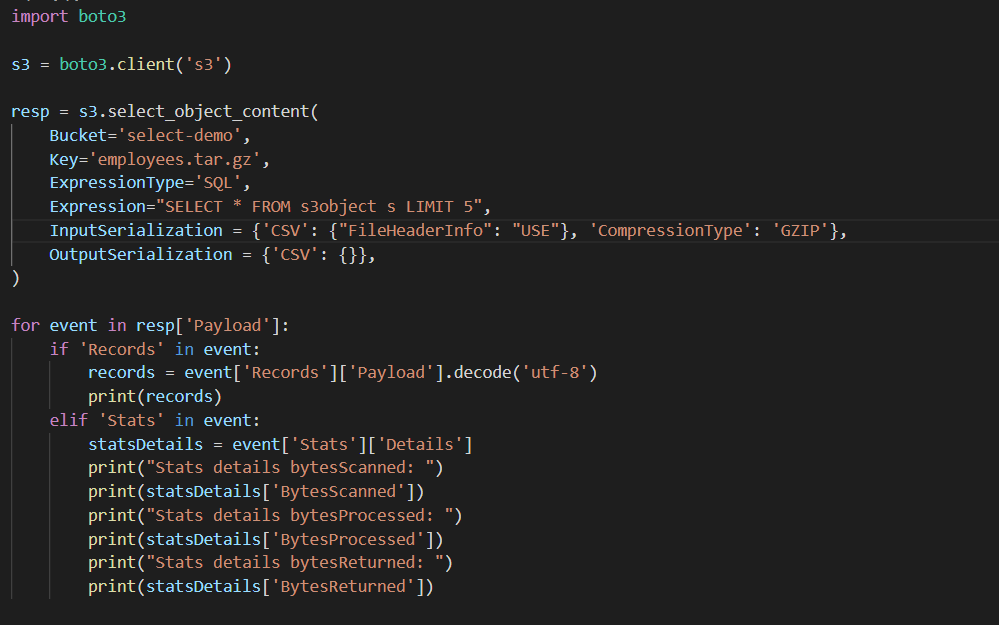
zip the same file using GZIP and upload it to s3
5. In the following image, the results for byteScanned are much lesser than the file without compression.
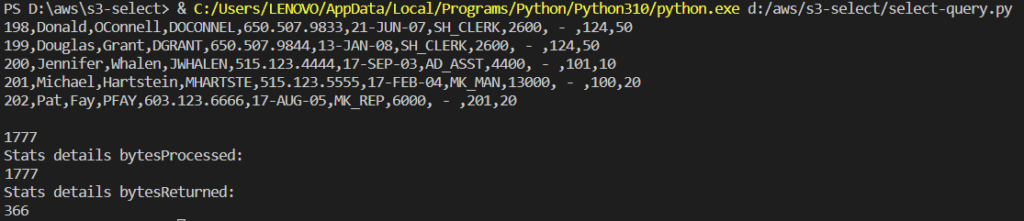
results for byteScanned
Conclusion
This was a hands-on demo to query s3 files using s3-select. It’s a handy tool for small-scale applications and can be a database. It can also be used as a tool for data analysis in which data cleaning can be performed to some extent using s3-select, and you don’t have to do it locally.
Thanks for reading!





